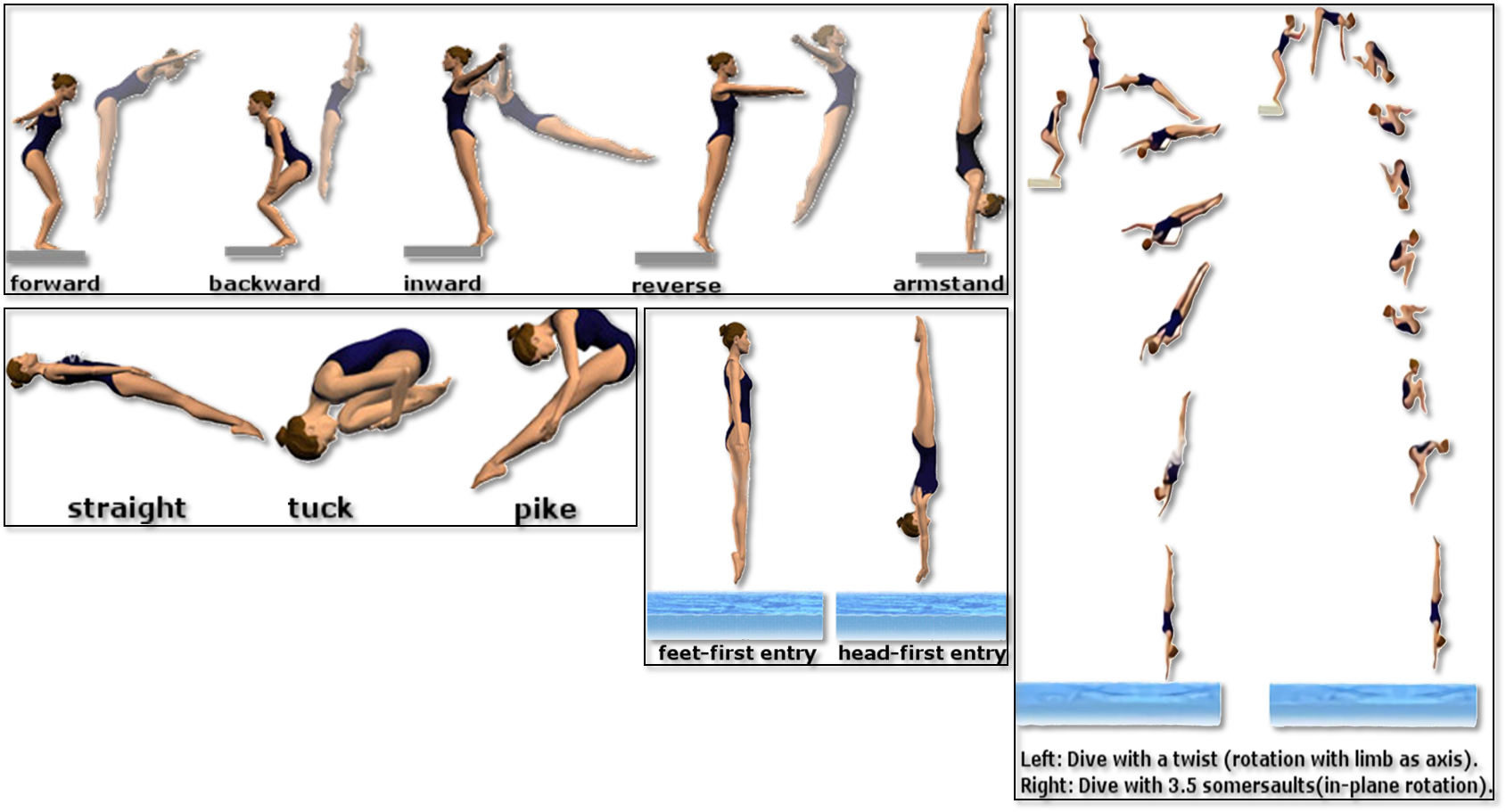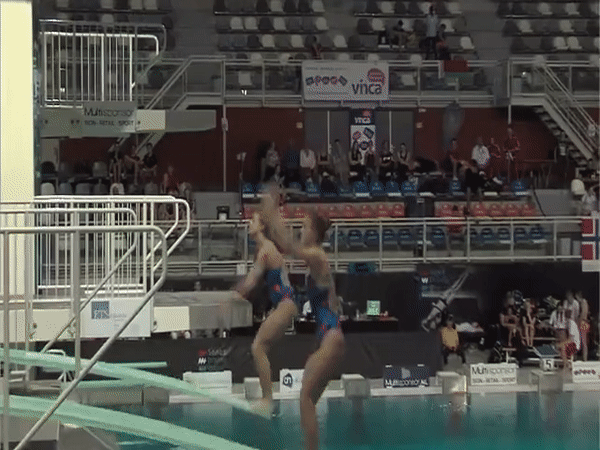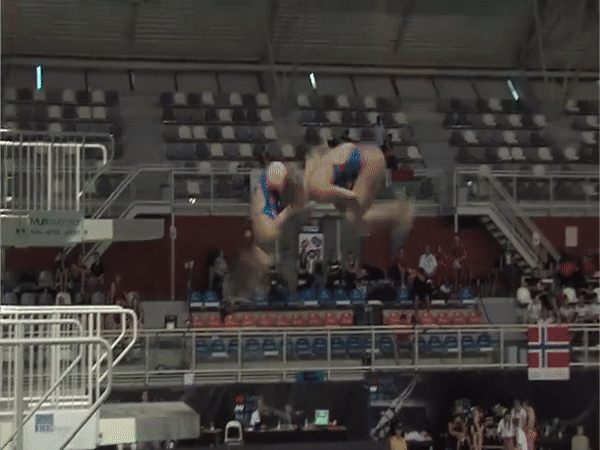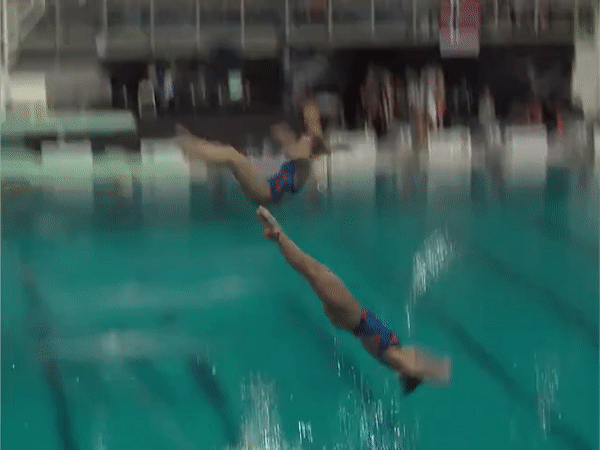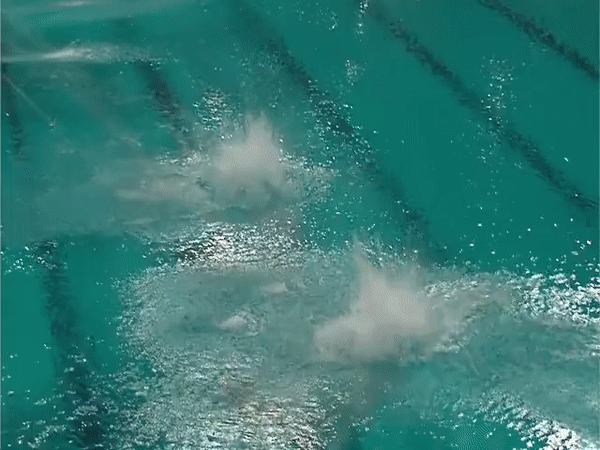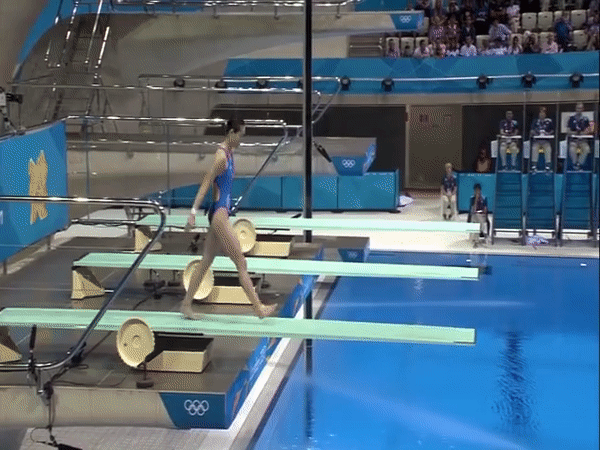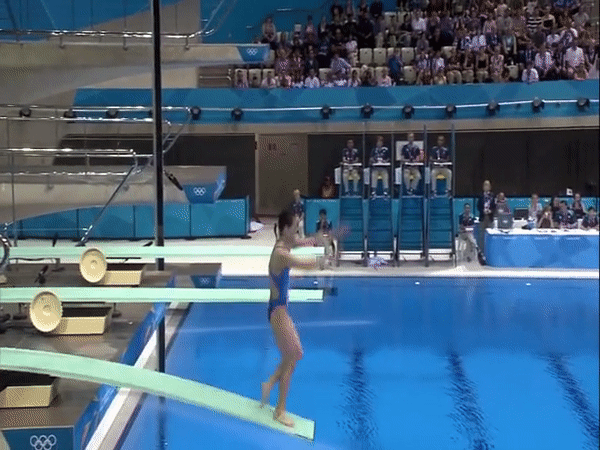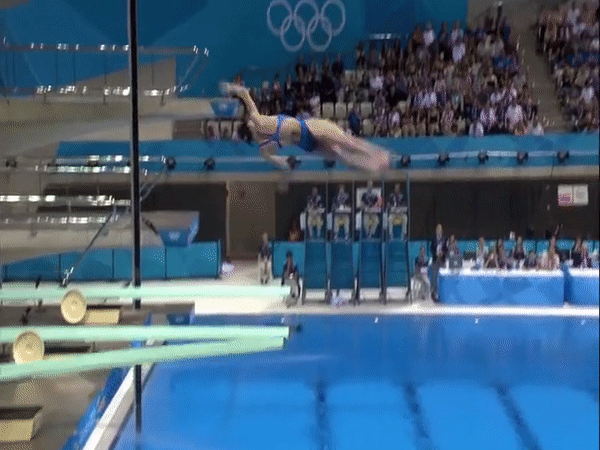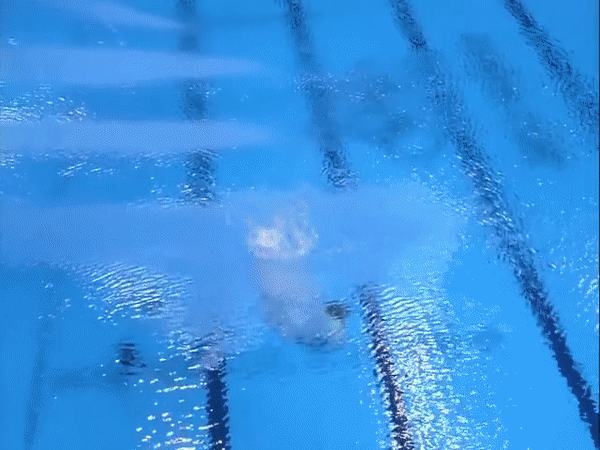| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

|
Diving48 Dataset |
||||||||
|
Diving48 is a fine-grained video dataset of competitive diving, consisting of ~18k trimmed video clips of 48 unambiguous dive sequences (standardized by FINA). This proves to be a challenging task for modern action recognition systems as dives may differ in three stages (takeoff, flight, entry) and thus require modeling of long-term temporal dynamics. Description Each of the 48 dive sequences are defined by a combination of takeoff (dive groups), movements in flight (somersaults and/or twists), and entry (dive positions). The prefix tree below summarizes all the dive classes present in the dataset.
The video clips of Diving48 are obtained by segmenting online videos of major diving competitions. The ground-truth labels are transcribed from the information board before the start of each dive. The dataset is partitioned randomly into a training set of ~16k videos and a test set of ~2k. Motivation This dataset was initially introduced in our ECCV'18 paper RESOUND: Towards Action Recognition without Representation Bias. The purpose was to create an action recognition dataset with no significant biases towards static or short-term motion representations, so that the capability of models to capture long-term dynamics information could be evaluated. This is in contrast to popular action datasets which are usually solvable through short-term modeling (e.g. two-stream convolutional networks). We selected the domain of diving because 1) there are many different divers per competition, 2) there are no background objects that give away the dive class, 3) the scenes tend to be quite similar in all dives, and 4) the divers have more or less the same static visual attributes. This implicitly addresses the scene, object, and person biases in our dataset. Download
10/30/2020 update -- Manually cleaned dive annotations, with poorly segmented videos removed:
9/30/2023 update -- The data is migrated to Nextcloud and download links are updated. Publication Please cite the following paper if you find this dataset helpful:
RESOUND: Towards Action Recognition without Representation Bias Contact |
||||||||
|
Examples |
||||||||
|
||||||||
![]()
©
SVCL